SRE
Overview
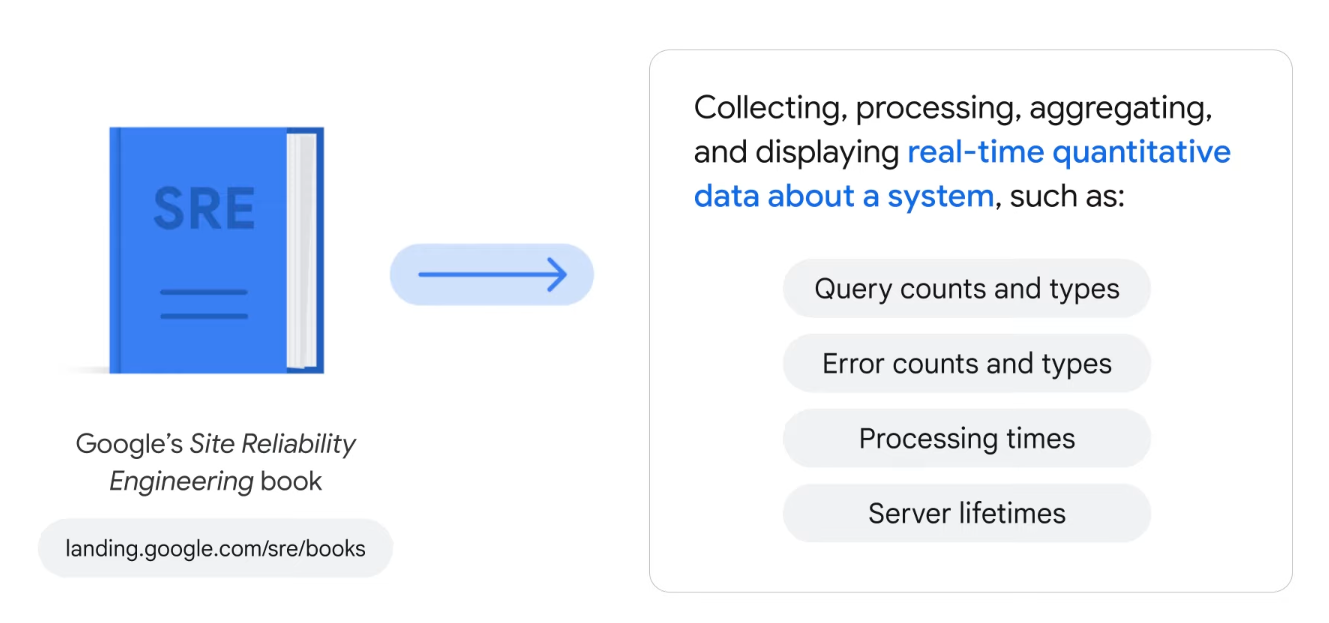
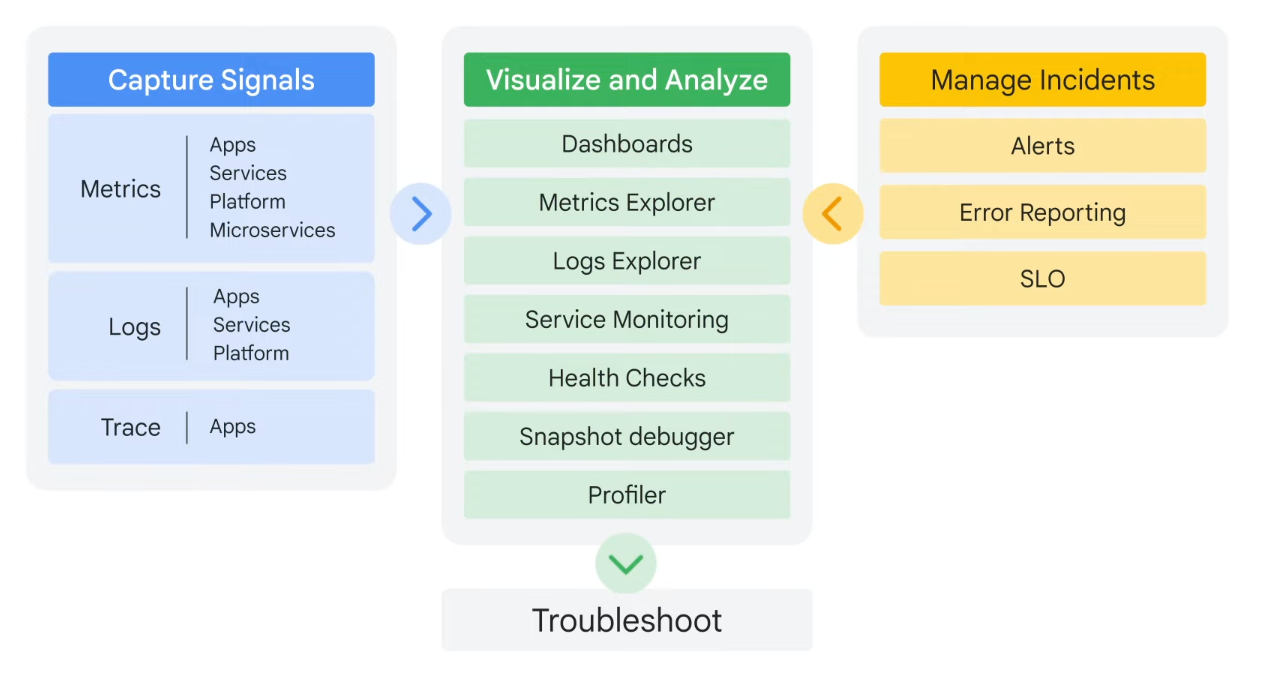

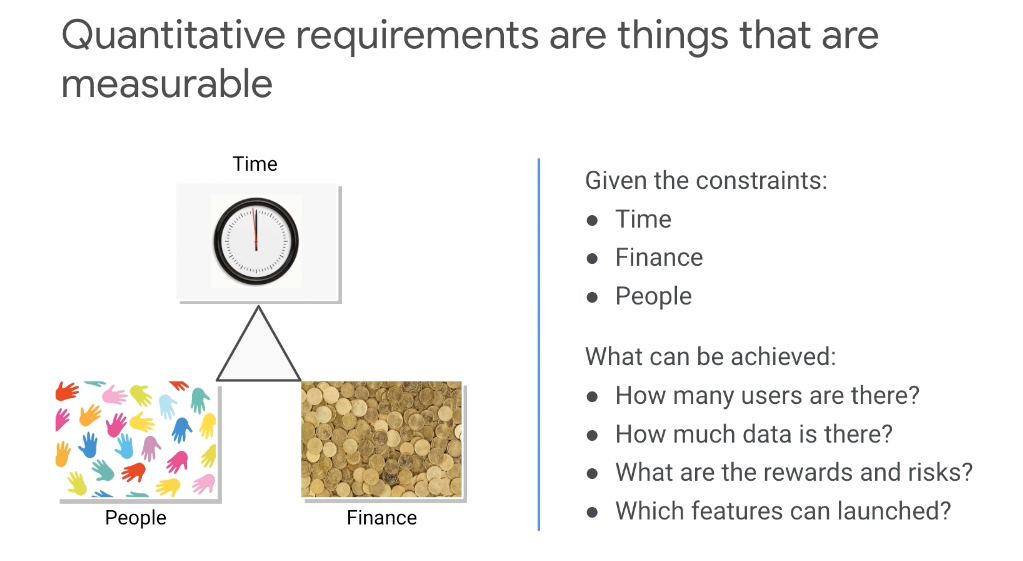
Requirements, analysis, and design
- Qualitative requirements define systems from the user's point of view
- Who
- Who are the users, developers, or stakeholders?
- What
- What does the system do?
- What are the main features?
- Why
- Why is the system needed?
- When
- When do the users need and/or want the solution?
- When can the developers be done?
- How
- How will the system work?
- How Many users will there be?
- How much data will there be?




Key performance indicators (KPIs)
- In business, common KPIs include
- Return on investment (ROI)
- Earnings before interest and taxes (EBIT)
- Employee turnover
- Customer churn
- In software, common KPIs include
- Page views
- User registrations
- Clickthroughs
- Checkouts
- KPI is not the same thing as a goal or objective
- Goal: Increase turnover for an online store
- KPI: The percentage of conversions on the website

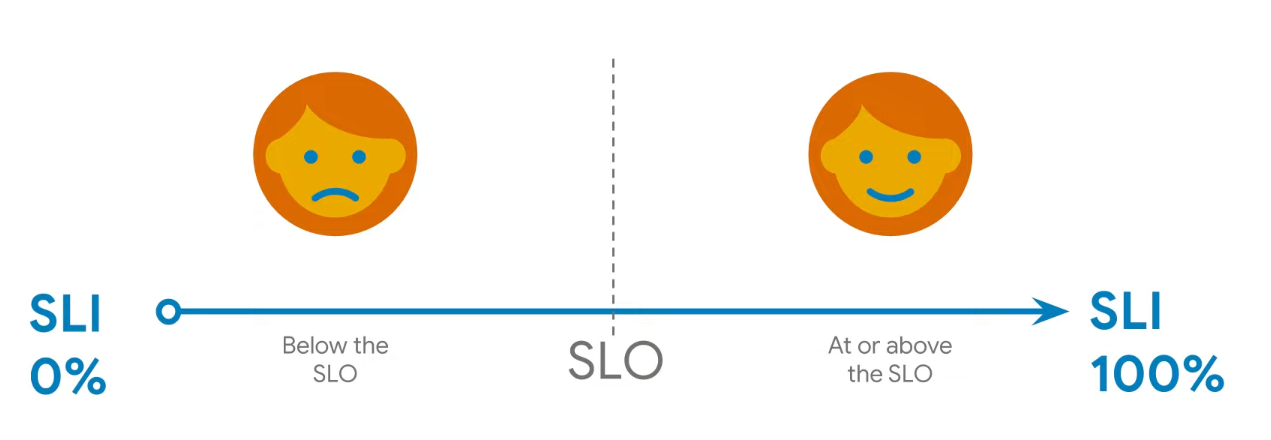
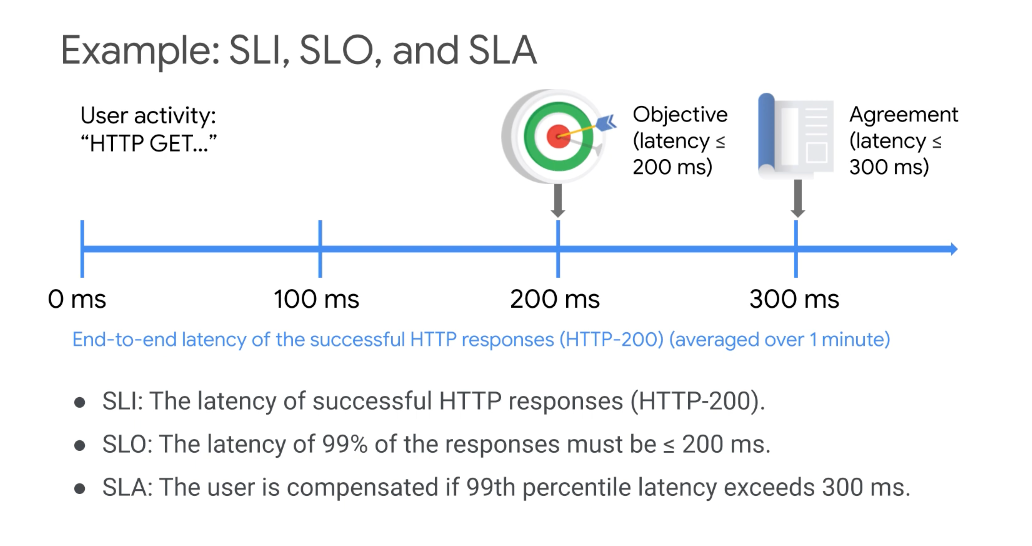
Service Level Indicator (SLI)
- SLIs are carefully selected monitoring metrics that measure one aspect of a service's reliability
- Ideally, SLIs should have a close linear relationship with your users' experience of that reliability, and we recommend expressing them as the ratio of two numbers: the number of good events divided by the count of all valid events
- Must be time-bound and measurable
- 3-5 SLIs per user journey

Service level objective (SLO)
- combines a service level indicator with target reliability
- If you express your SLIs as is commonly recommended, your SLOs will generally be somewhere just short of 100%, for example, 99.9%, or "three nines."
- Must be achievable and relevant
- Tips
- The goal isn't to make SLOs as high as possible
- The goal is to make them as low as you can get away with while still making users happy (That's why it's important to understand your users)
- The higher you set the SLO, the higher the cost of computer resources (redundancy) and operations effort (people time)
- Applications should not significantly outperform their SOLs, because users come to expect the level of reliability you usually give them

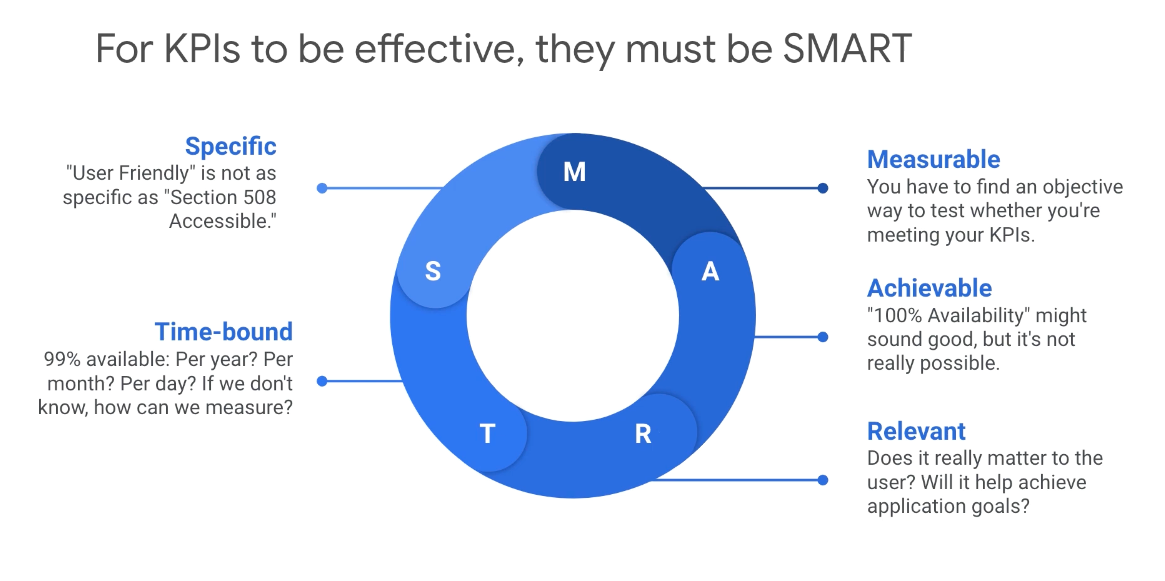
S.M.A.R.T
- Specific
A question such as “Is the site fast enough for you?” is not specific; it's subjective. A statement such as “The 95th percentile of results are returned in under 100 milliseconds” is specific. - Measurable
A lot of monitoring is numbers, grouped over time, with math applied. An SLI must be a number or a delta; something we can measure and place in a mathematical equation. - Achievable
- Relevant
- Time-bound
Do you want a service to be 99% available? That’s fine. Is that per year? Per month? Per day? Does the calculation look at specific windows of set time, from Sunday to Sunday for example, or is it a rolling period of the last seven days? It can't be measured accurately if we don't know the answers to those questions.
Service Level Agreements (SLA)
- Commitments are made to your customers that your systems and applications will have only a certain amount of “downtime.”
- An SLA describes the minimum levels of service that you promise to provide to your customers and what happens when you break that promise
- If your service has paying customers, an SLA may include some way of compensating them with refunds or credits when that service has an outage that is longer than this agreement allows
- To give you the opportunity to detect problems and take remedial action before your reputation is damaged, your alerting thresholds are often substantially higher than the minimum levels of service documented in your SLA
- Not all services have an SLA, but all services should have an SLO
- Your SLO thresholds should be stricter than your SLA

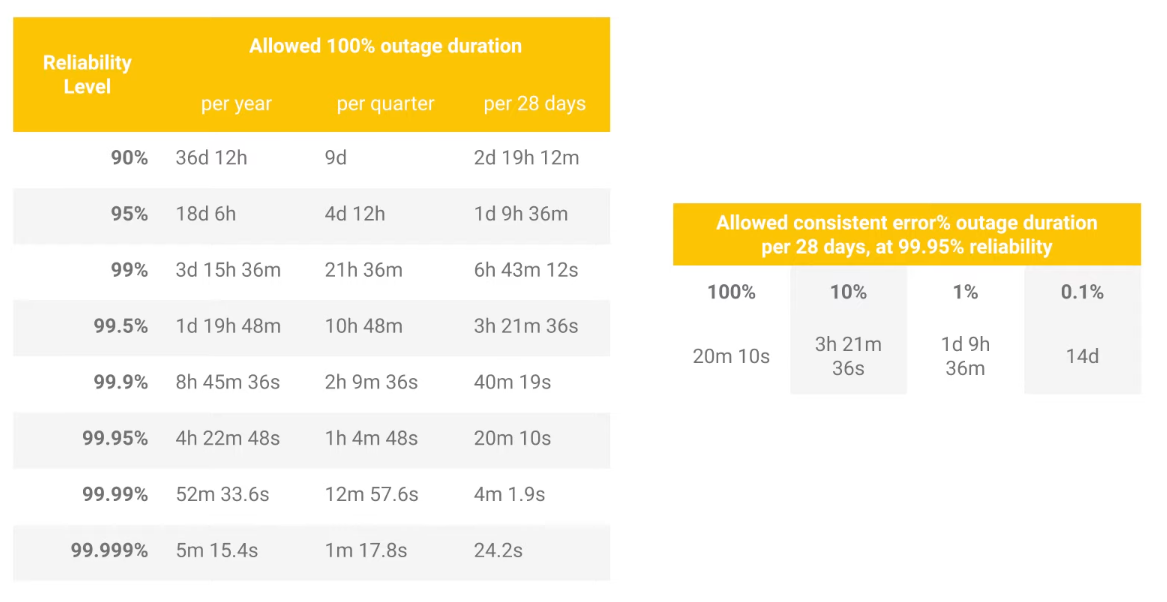

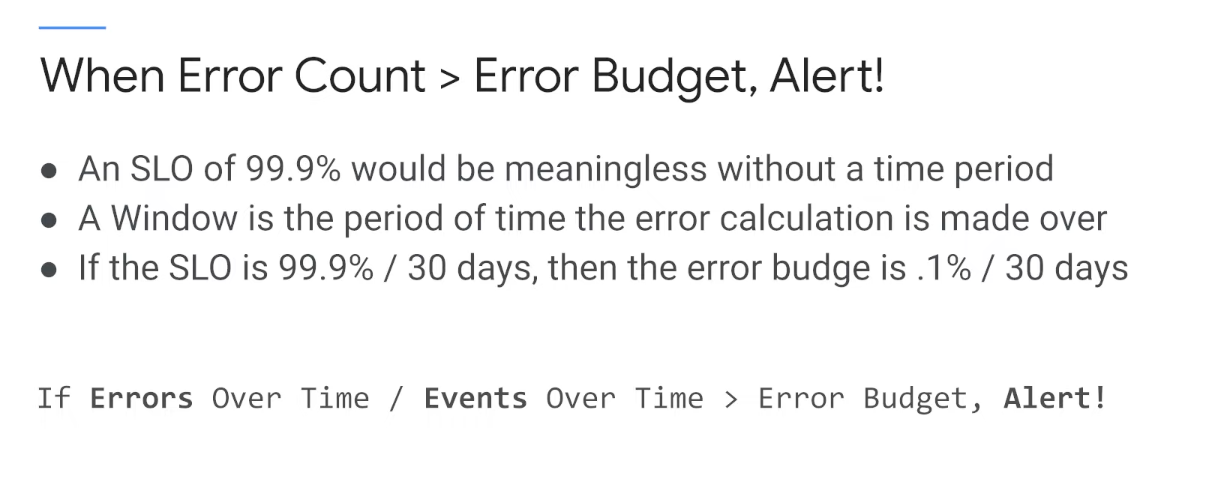
Error Budget
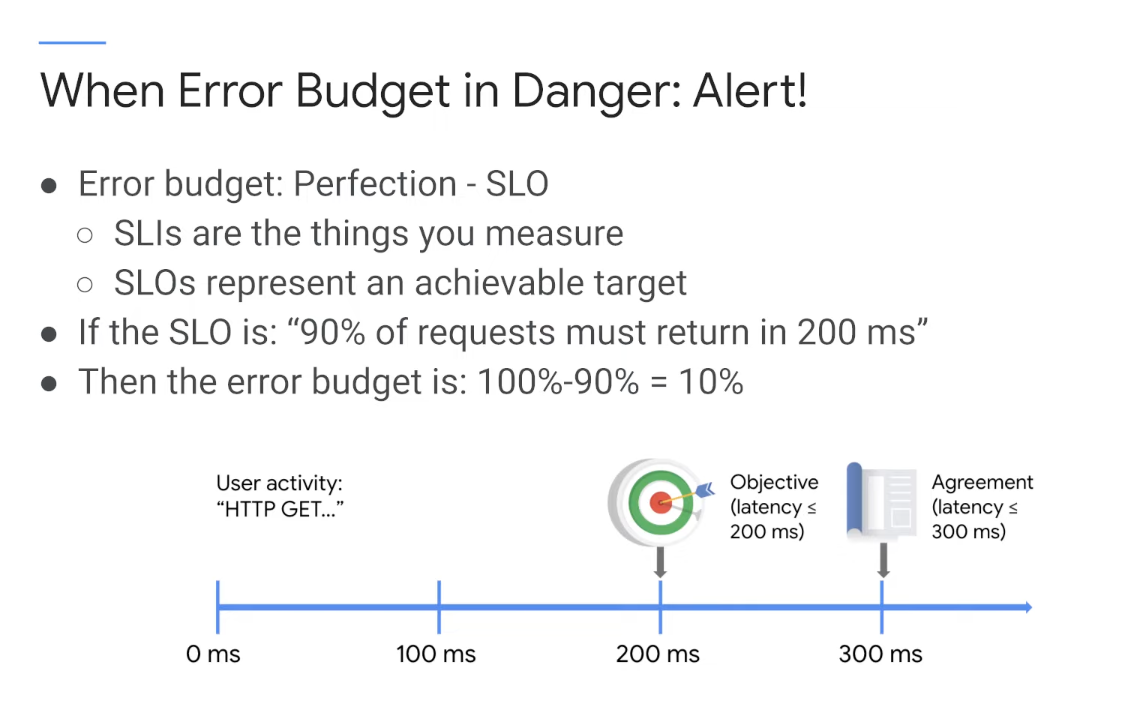
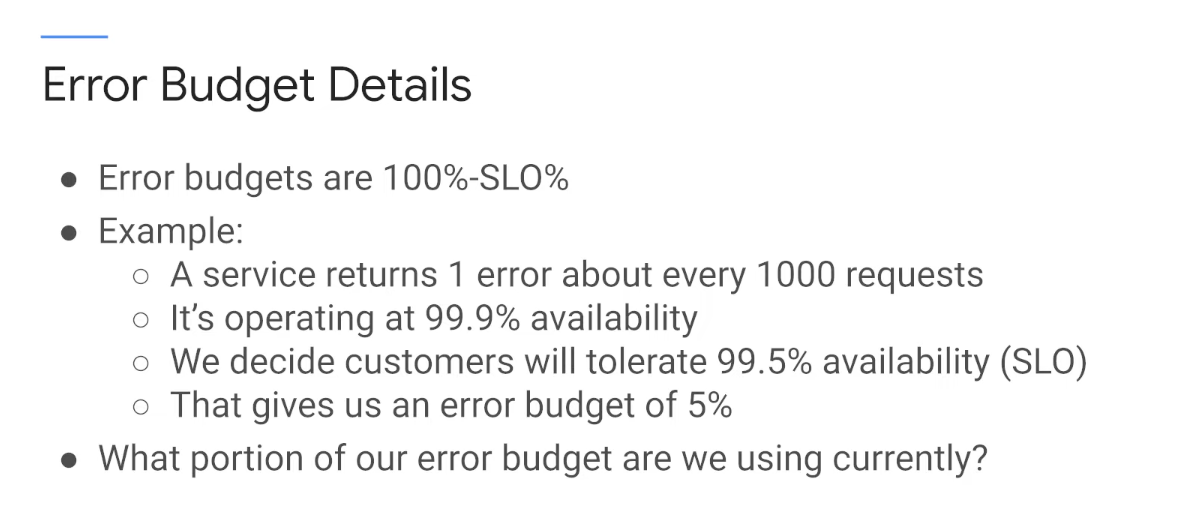



Alert




Four Golden Signals
- Latency
- Page load latency
- Number of requests waiting for a thread
- Query duration
- Service response time
- Transaction duration
- Time to the first response
- Time to complete return
- Traffic
- # HTTP requests per second
- # Requests for static vs. dynamic content
- Network I/O
- # Concurrent sessions
- # Transactions per second
- # of retrievals per second
- # of active requests
- # of write ops
- # of read ops
- # of active connections
- Saturation
- % memory utilization
- % thread pool utilization
- % cache utilization
- % disk utilization
- % CPU utilization
- Disk quota
- Memory quota
- # of available connections
- and # of users on the system
- Errors
- Wrong answers or incorrect content
- # 400/500 HTTP codes
- # failed requests
- # exceptions
- # stack traces
- servers that fail liveness checks
- And # dropped connections
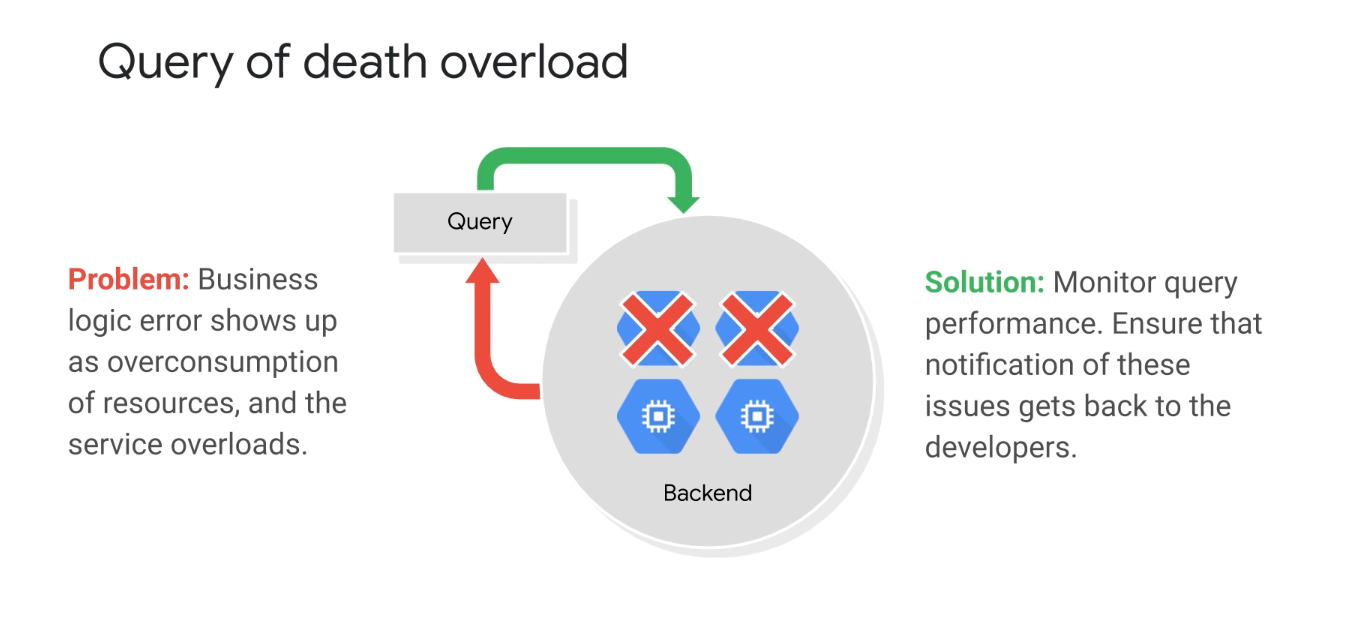
Handling Excess Loads
- Load Shedding
- API limits
- Streaming Data
- Reduce Quality of Service
- Instead of talking to a recommendations API, return a hardcoded set of products
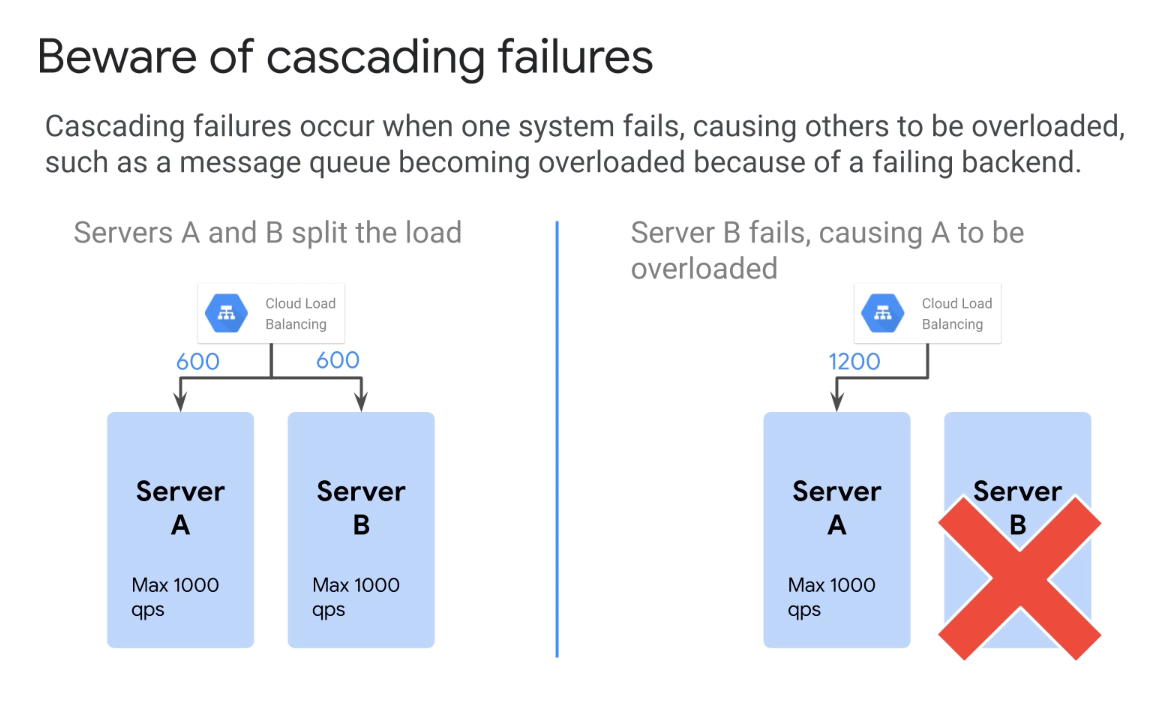
Avoiding Cascading Failures
- Plan to avoid thrashing
- Circuit Breaker
- Reduce Quality of Service
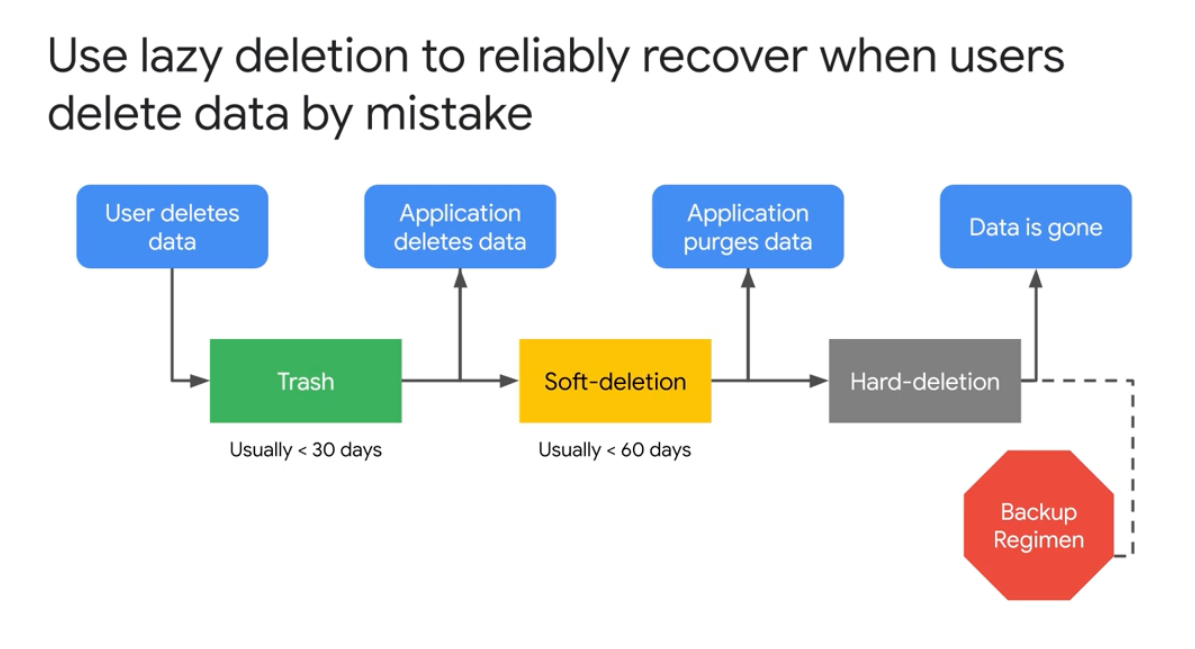
Postmortem
- Impact
- Root Causes and Trigger
- Detection
- Resolution
- Quantifiable metrics
- Lessons Learned
- Timeline
- Action items
Incident Management
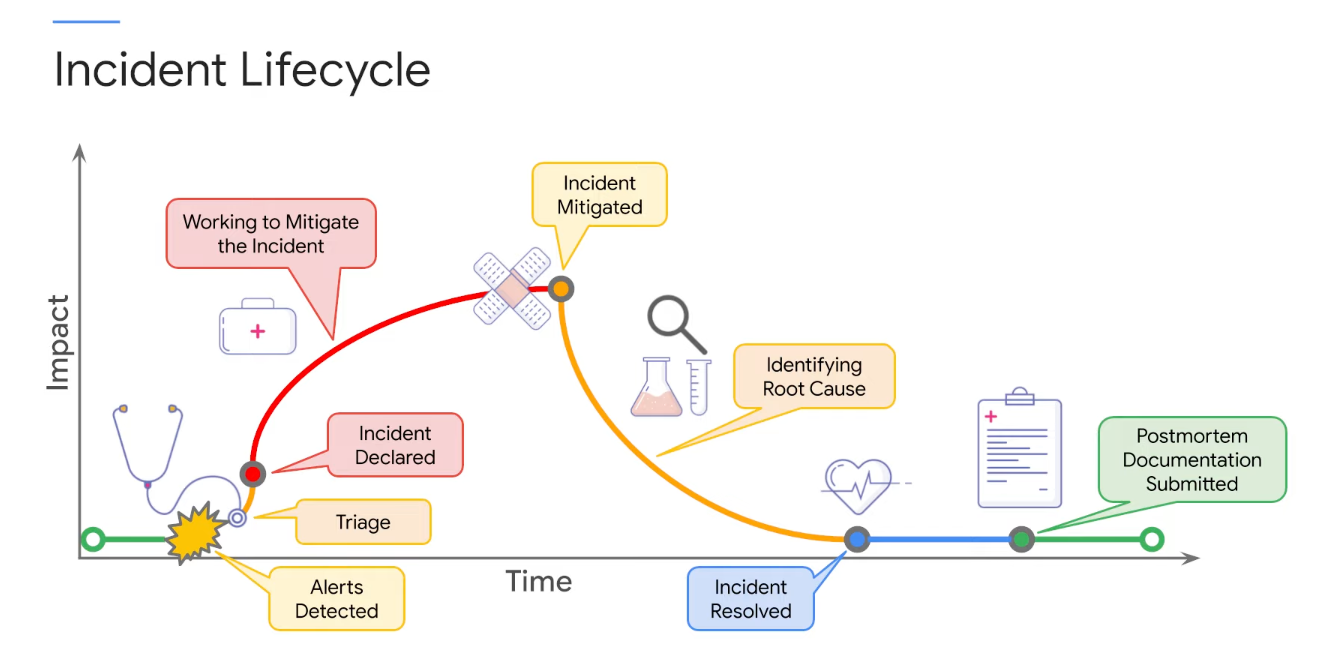
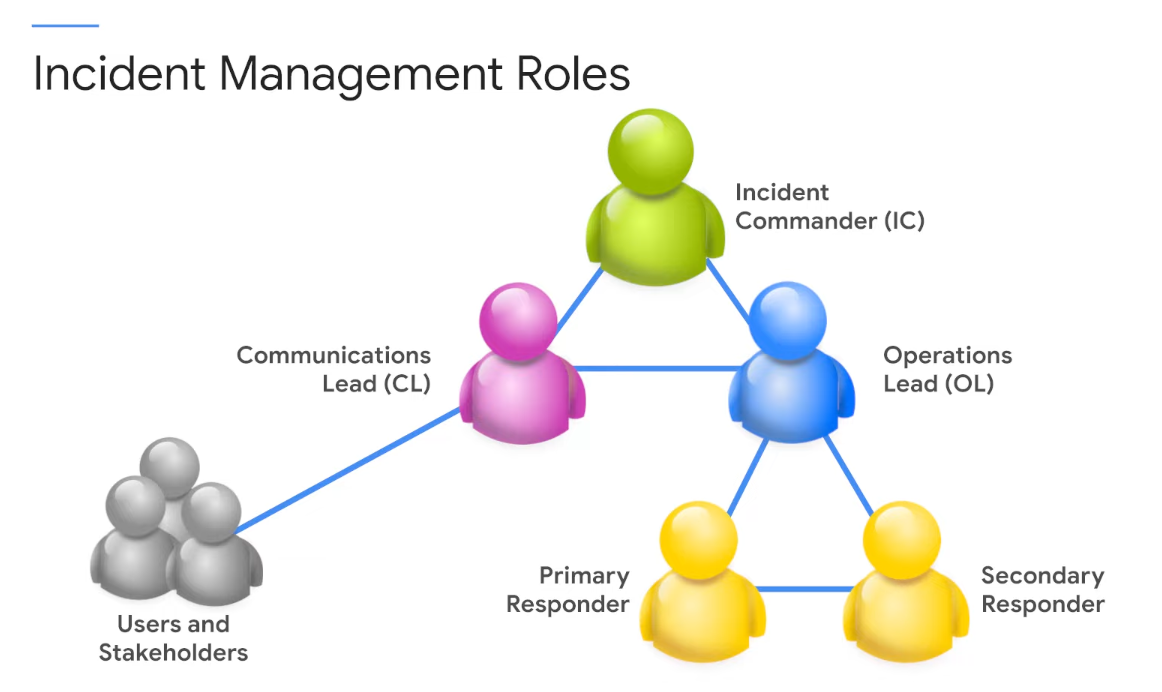
Note
Blameless Culture
Fix problems, not people
Reliability





Design

Quote
"Hope is not a strategy" - Traditional SRE saying